
2008年03月12日
AMDのクアッドCPU Propusは「L3のないダイ」として製造
AMDのクアッドCPU Propusは「L3のないダイ」として製造されるようです。
・ L3無しのQuad-Core“Propus”は専用ダイで生産される- 北森瓦版
・ Deneb 0MB L3 doesn’t have L3 cache disabled - Fudzilla
AQ4に発表予定といわれているAMDの45nmクアッドコアにはL3のサイズによって2つのバリエーションがあり、L3を現状の2MBから6MBに増量させたDenebとL3をなくしたメインストリーム用Propusが用意されます。
従来だとL3のないCPUを製造する場合は、L3のあるCPUのL3をわざわざ無効にするという方法がとられることが多かったのですが、Propusの場合は最初からL3のないダイとして製造されるために、市場に出回るクアッドコアCPUの中では最も小さなCPUになり、製造コストが抑えられることになります。
しかもL3キャッシュがないことによるデスクトップ CPUのパフォーマンスダウンはベンチマーク以外はとても小さいようです。またこちらでも紹介していますように、PropusはDenebに比較してTDPが低減しており、その面でも貢献しそう。
DenebやPropusのクロックは不明ですが、Propusはなかなかおもしろい存在になりそうです。
通販情報
[Phenom CPU] TSUKUMO![]() 、
、SOFMAP、クレバリー、ドスパラ、FAITH
![]() 、価格比較
、価格比較
[790FXマザー] TSUKUMO、
SOFMAP、クレバリー、ドスパラ、
TWOTOP、
FAITH
[X2 5000+ Black Edition] :SOFMAP、TSUKUMO
![]() 、ドスパラ、クレバリー、
、ドスパラ、クレバリー、FAITH
Posted by nueda at 2008年03月12日 03:48 JST | トラックバック | ホームに戻る
だったら、ベンチマーク専用CPUのほうが必要無いような気がします
Posted by: INTELAMD at 2008年03月12日 12:45懐かしのDuronを思い出しました。
Duronも安価なわりに高性能でOC耐性も高く人気でしたねぇ。
逆にベンチ専用じゃないCPUはいらないと感じるのは私だけでしょうか・・・。
Posted by: 市川 at 2008年03月12日 14:51もっとクロックが早くなる予定だったんでしょう。
キャッシュないほうが回せて早かったりしてね。
確かにL3なんてゲームベンチぐらいしか効かないからね。そっちのほうが要らないかもしれませんね。
Posted by: No Deneb at 2008年03月12日 15:42広報に回すベンチ専用CPUも
実際に売り出す安価なCPUも
どっちも必要
ベンチでトップ取れれば下位グレードも売れますからね。
(ブランド効果かしら?)
選択肢が増えて消費者には喜ばしいことなのに
イラナイとかいう意見が出るのはちょっと分かりません。
デスクトップにはL3付きは要らないと言う事にもなりますけど。
性能で負けている以上、L3で少しでも性能の上積みが必要なんでしょうね。
L3有りで252mm2、L3無しなら170mm2程度で作れる以上、コスパーは無しのほうがいい筈なんで。
うーん
もちろん両方問題なくできれば、それがいいと思います
が、どちらも専用ダイのようですから、変に作りわけて
失敗(あるいは片方が遅延など)しないかちょっと心配
というのはあるかもしれませんね^^
Core2Quadと利用用途が被る部分をPropusにして安価で攻め、Phenomが元々合う用途へDenebという感じでしょうか?
結構用途等も考えれず一部のベンチ等で評価してしまう方が居るので、その分をPropusの値段で打ち消すような効果がでるかもしれませんね
評価が良くなれば搭載システムも多くなりますし、仕事等で性能を欲している所ではK8/K10が素晴らしい性能を発揮してくれる事も多いのでこれによって手に入りやすくなれば嬉しいのですが
L3キャッシュがきちんと4つのコアで共有されてるのなら
大容量のL3キャッシュは(ある種の用途には)有り難いですね。
マルチスレッドでなおかつスレッド間同期を頻繁に行う
(データ共有する)タイプのソフトなら有効に働きそうです。
ロストプラネットとか。
一方でメインメモリへのアクセスレイテンシは
L3がある事で少し伸びそうなのが辛いところですか。
マルチコアに最適化したアプリを使うつもりが無い限り、
デスクトップ用途にはL3が無い方が向いてる気がします。
ソフトウェアの進歩状況によって大きく評価が
大きく変わるでしょうね。
スレッドの数が多くなれば、キャッシュが少ないことの
デメリットは簡単に隠蔽できるでしょうけど、逆なら・・・
そう考えると、トライコアって今の中途半端な
ソフトの対応状況には合っているのかもしれませんね(笑)
PhenomのキャッシュはVictimキャッシュですから、L3を介してデータの共有は行なわれていないのでは?
L3はあくまでL2から溢れたデータの溜まり場で、中身は4つのコアで4つの領域に分かれているはずです。
コア間のデータ移動はクロスバースイッチ経由ですよね。
IntelのC2Qでは共有L2を介して2コア間でデータ移動が起きますが。
だからこそPhenomからL3をカットしてもそれほど性能低下しないということでもあり、L2の容量をもっと増やせばもっと性能あがるのに、という根拠でもあります。
Posted by: forz at 2008年03月13日 03:10fozさんの言うとおりPhenomのL3は4領域(若しくは稼働CPU数の領域)に分割されて使用され、データ移動はクロスバスイッチ経由です。
各コアに割り当てられる容量は必要量に応じて動的に割り当てられるそうですが。
これがL3全領域での共有になればL3の存在意義が増すでしょうね。
L3省略の3コア・4コアが出るのなら、L2容量各1MB・L3無しという存在も欲しいところですね。
L3とL2間やL1,L2間同士の移動が起こる為に結局L3無しと同じ速度になるだけでは?
ベンチではサイズによってL3に留まるようでL3の効果が得られてます
L3へのアクセスとメモリアクセスを重なるようにしても両方余り性能が低下せずアクセスできているようです
L3がかなり遅い為スコアは微妙なものですが、実際のアプリでは効果が出ていると思うのですが
他の部分も変わりすぎていてL3の効果なのかがはっきり分からない部分もあったりします
あと、遅くなってる部分はプリフェッチが変わっていて他CPU向けの最適化が施されていると逆に遅くなるようです
sandraの古いバージョンのメモリアクセスが最適化有無が一番はっきり出ますが、最適化有効で5.5GB/s、無効で7.5GB/s、新しいバージョンで9.5GB/sと言う凄い物になっています
これによってL3が足を引っ張ってると間違われたりしていますし、L3自体は割と良いのでは?と思うのですが
forzさん、しーぽんさんの指摘された事(Phenomの
L3キャッシュはコア間のデータ共有用途に使えるのか)は
私も気になっていたので改めてWeb上で読める資料を
チェックしてみました。
「PhenomのL3キャッシュはコア間のデータ共有をしない」と言う
話の情報源は大原雄介氏の以下の記事ですよね?
http://journal.mycom.co.jp/special/2008/phenom01/012.html
ところが後藤弘茂氏のBarcelonaに関する記事では
「共有ラインをL3キャッシュに残す事も可能」とされています。
http://pc.watch.impress.co.jp/docs/2006/1016/kaigai312.htm
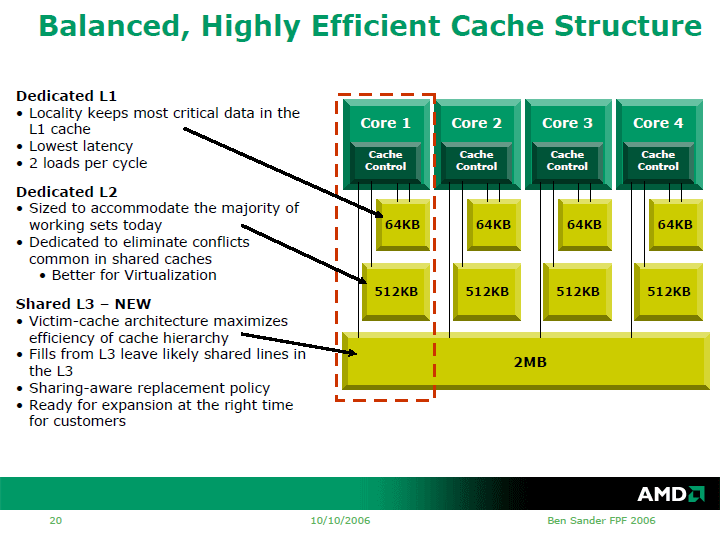
特に掲載されているAMD製の解説図では
http://pc.watch.impress.co.jp/docs/2006/1016/kaigai312_07l.gif
"Shared(共有)L3"とハッキリ謳われており、
"・Fills from L3 leave likely shared lines in the L3"
"・Sharering-aware replacement policy"
とコア間でL3キャッシュにあるラインがシェアされる事が示唆されています。
この違いはどういう事なのか?
真相は以下のAMD Developer Blogsを読むとだいぶ分かってきます。
http://forums.amd.com/devblog/blogpost.cfm?catid=209&threadid=92542
Phenomはa "mostly exclusive victim" cacheを持ちますが
それは完全なexclusive victim cacheでは無いのです。
実際、うまく操ればL3キャッシュ経由で高い転送レートを保って
データ転送できるとしています。
ただし、そうするには幾つかプログラミング上の注意点があるようです。
(私には実際の細かい点が良く分かりませんが)
大原氏の実験で転送レートが低く出ているのは検証に用いたソフトが
Phenom固有の要請を満たしていない為では無いかと思います。
実際、このブログで筆者のKent Knoxさんは
"In general, the AMD Phenom cache is optimized for widely shared data"
と述べてますし。
(長文すみません。私はPC関係のブログを持ってませんのでご容赦を)
何をL3に残すか残さないか判断するロジックそのものがレイテンシ-低下につながるんでしょうな。
とは言えPhenomでオールコピーだと最大2.5MBもの重複になりL3 6MB積んだとしても、3.5MBしか残らない。
あまり効率的はいえませんね。
kyouさん、
「何をL3に残すか残さないか判断するロジックそのものがレイテンシー低下につながる」
とはつまりそれが
「CPUコアがL3からデータフェッチする際のアクセスレイテンシー低下につながる」
と言う意味でしょうか?
私個人的にはハードウェアロジックが判断するのだからCPUからのリクエストに
答えておいて(データ転送を始めて)からそのラインを残すか残さないか、
並行して判定する事も十分可能では無いかと思えます。
いずれにしろKent Knoxさんのthe accompanying paper (coming soon)
なるものを早く読みたいところです。
真相がハッキリしたところで大原氏には
(もし氏が間違っていたとしたら)訂正記事などを書いて頂きたいと
思いましたので一応マイコミジャーナルの「ご意見・ご感想」欄に
一連の趣旨をメールしておきました。
ところで、以前AMDの兄貴が言っていた
まだWebには漏れてない隠し玉がある
ってまさかコレのことなんでしょうか・・・。
(書込時に「、」か「。」が必要です。内容によっては削除しますので、ご了承ください)
{kind=link}